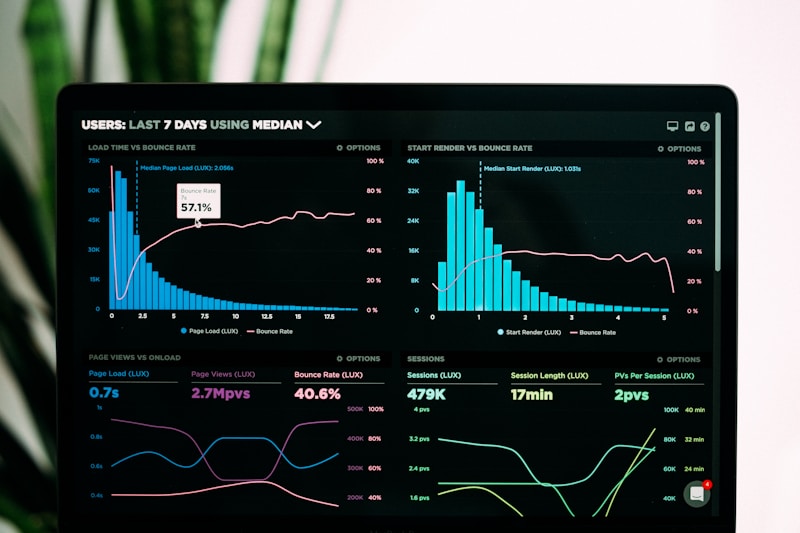
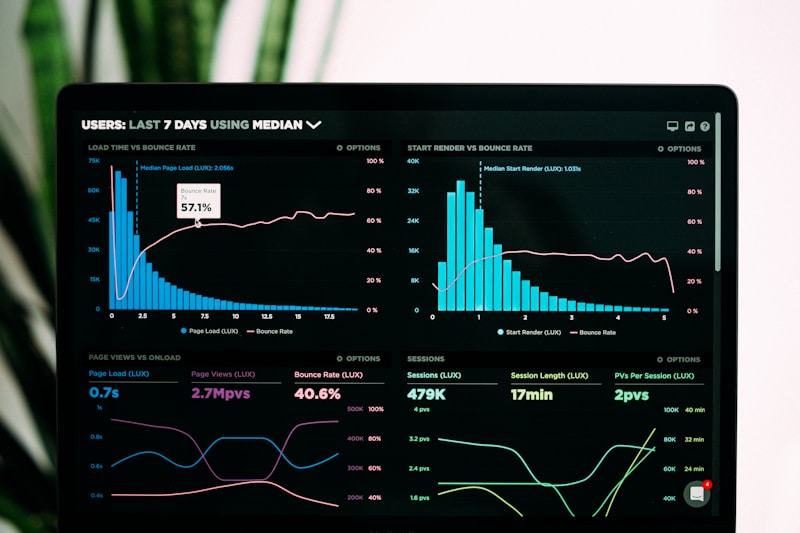
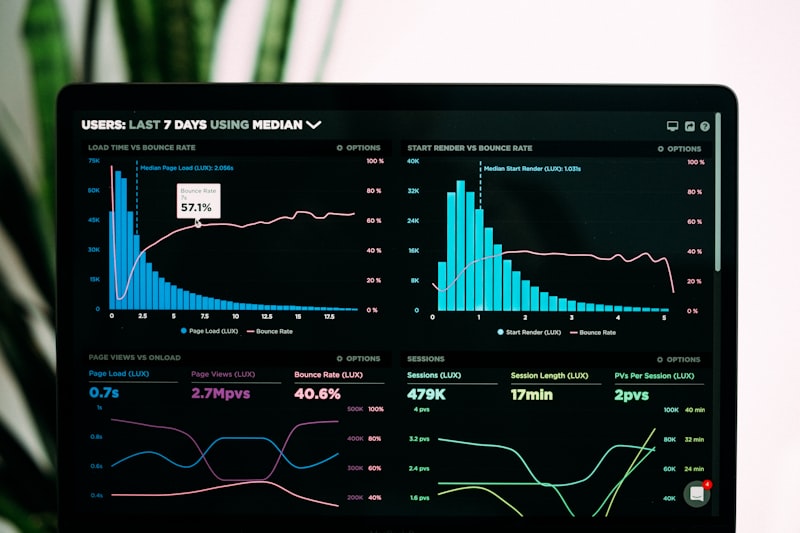
Spark 自适应查询执行 AQE 原理与生产实战:动态优化提升 Spark SQL 性能
引言:为什么需要自适应查询执行? 在 Apache Spark 的早期版本中,SQL 查询的性能高度依赖于开发人员对数据的了解程度和手动调优经验。一个常见的场景是:开发者在开发环境设定了一个合理的 shuffle 分区数(如 200),但到...
引言:为什么需要自适应查询执行? 在 Apache Spark 的早期版本中,SQL 查询的性能高度依赖于开发人员对数据的了解程度和手动调优经验。一个常见的场景是:开发者在开发环境设定了一个合理的 shuffle 分区数(如 200),但到...

引言:数据读写是Spark性能的”隐形瓶颈” 在Spark生产环境中,许多开发者把精力集中在内存调优、Shuffle优化和并行度设置上,却往往忽视了一个关键环节——数据读写。事实上,根据业界对多个Spark生产集群的...
数据倾斜(Data Skew)是 Spark 生产环境中遇到的最棘手的性能问题之一。当某个分区的数据量远大于其他分区时,整个作业的执行时间会被这个慢任务拉长,导致集群资源利用率低下,甚至引发 OOM 异常。本文将深入剖析数据倾斜的底层原理,...

引言:数据架构的演进之路 大数据技术在过去十年经历了飞速的演进,从最初的Hadoop HDFS + MapReduce批处理架构,到Spark带来的内存计算革命,再到数据湖(Data Lake)概念的兴起,每一步都推动着数据处理能力的边界不...

前言:为什么Spark内存管理至关重要 Apache Spark 作为大数据处理领域的事实标准框架,其核心优势之一就是基于内存的计算模型。相比 Hadoop MapReduce 的磁盘迭代模式,Spark 能够将中间结果保存在内存中,大幅提...

在大数据处理领域,实时流计算已经成为企业数字化转型的核心能力之一。Apache Spark 的 Structured Streaming 模块自 Spark 2.0 引入以来,以其声明式 API、Exactly-Once 语义保证和与批处理...
在Spark SQL的实际开发中,Shuffle是影响作业性能的关键瓶颈之一。每当执行groupBy、join、repartition等宽依赖算子时,数据需要在不同节点间重新分布,这个过程就是Shuffle。不合理的Shuffle配置会导致...

关于SBT你需要知道的那些事 之前在做一个有关spark的项目的时候,需要使用sbt构建scala代码,以前主要用maven,gradle也用一点,但是sbt实在陌生,摸索了一阵,把自己在使用sbt中最需要了解的东西记下来,以备同样不熟悉的...
spark中如何禁用和开启snappy压缩 spark的作用中如果需要从hdfs中读写较大的结果,最好开启snappy压缩,已取得较好的性能。 开启或者禁用snappy压缩的方法 初始化sparkConf配置 123var conf = n...